چگونه می توان با استفاده از دیپ لرنینگ در پایتون ، FaceID را در

آنچه در این نوشته خواهیم داشت
- مقدمه:
- مفهوم FaceID:
- چهره ها و اعداد در شبکه های عصبی ( شبکه عصبی Siamese )
- مزیت نهایی استفاده از دیپ لرنینگ در تشخیص تصویر
- اجرای FaceID در Keras
- آزمایش شبیه سازی FaceID
مقدمه:
یکی از ویژگی های بحث برانگیز آیفون X روش باز کردن قفل با استفاده از تشخیص چهره ( FaceID ) است که جایگزین TouchID شده است. اپل پس از ساخت تلفن بدون حاشیه، مجبور شد روش جدیدی را برای باز کردن قفل گوشی به شکلی آسان و سریع ایجاد کند. در حالی که برخی از رقبا به قرار دادن سنسور اثر انگشت در موقعیتی جدید بسنده کردند، اپل تصمیم گرفت در شیوه باز کردن تلفن روشی نوآورانه و انقلابی را ایجاد کند؛ یعنی نگاه کردن به صفحه نمایش گوشی! به لطف بهره گیری از یک دوربین جلوی پیشرفته و بسیار کوچک، آیفون X قادر به ایجاد نقشه سه بعدی از چهره کاربر است. علاوه بر این، تصویری از چهره کاربر با استفاده از یک دوربین مادون قرمز ضبط می شود که نسبت به تغییرات در نور و رنگ محیط پایداری بیشتری دارد. با استفاده از دیپ لرنینگ ، تلفن های هوشمند قادر هستند با جزئیات کامل تری چهره کاربر را ضبط کنند، بنابراین هر بار که تلفن توسط صاحب آن برداشته می شود او را تشخیص می دهند. در کمال تعجب، اپل اظهار داشته است که این روش حتی از TouchID نیز ایمن تر بوده و میزان خطای برجسته آن 1:1000000 است.
ما به نحوه ایجاد این فرآیند با استفاده از دیپ لرنینگ و چگونگی بهینه سازی هر مرحله تمرکز کردیم. در این مقاله، نشان می دهیم که چگونه الگوریتم شبیه به FaceID را می توان با استفاده از Keras پیاده سازی کرد. آزمایش های نهایی با استفاده از Kinect، یک دوربین RGB بسیار محبوب، که دارای خروجی بسیار مشابه دوربین های جلوی آیفون X است، انجام شده اند.
مفهوم FaceID:
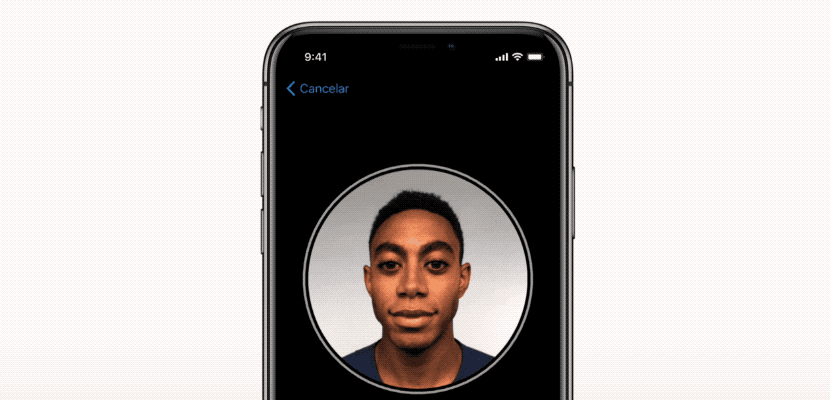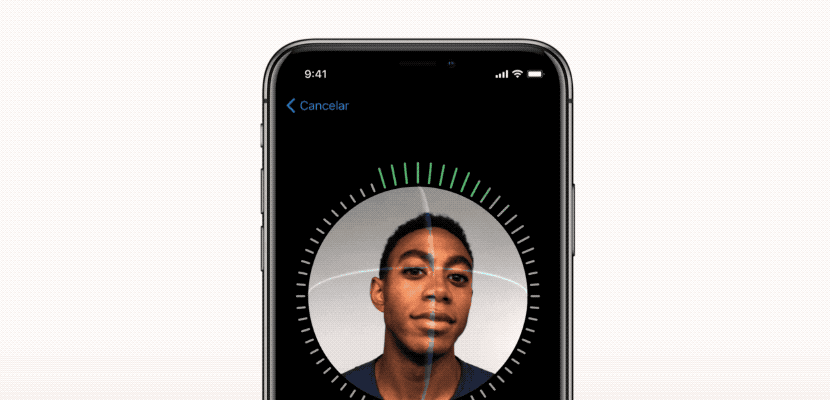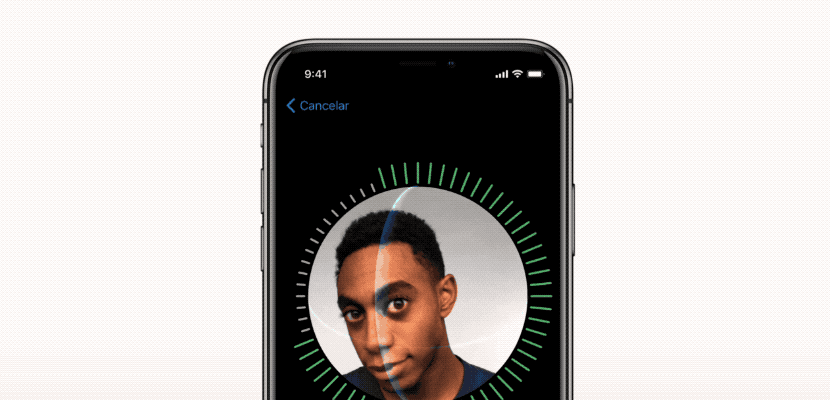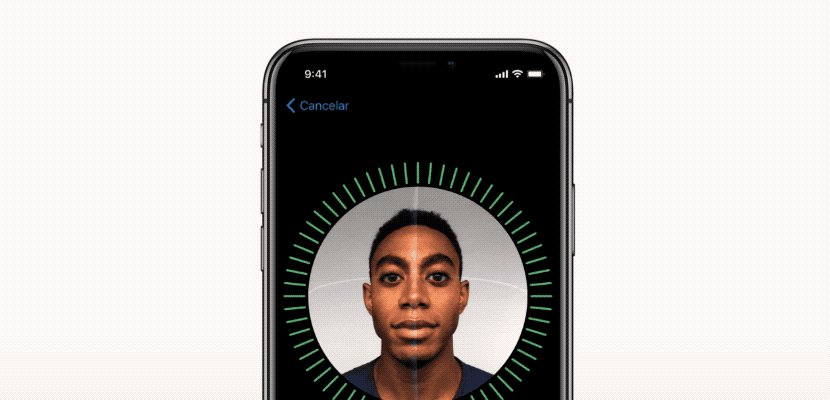
فرآیند تنظیم FaceID
شبکه های عصبی FaceID عملکرد پیچیده ای دارند. اولین قدم، تجزیه و تحلیل دقیق نحوه عملکرد FaceID در آیفون X است. در TouchID، کاربر مجبور است ابتدا با لمس مکرر حسگر، اثر انگشت خود را ثبت کند. پس از حدود 15 نمونه گیری مختلف، تلفن هوشمند فرایند ثبت را تکمیل کرده و TouchID آماده فعالیت خواهد بود. به طور مشابه در FaceID نیز کاربر باید صورت خود را ثبت کند. فرایند بسیار ساده است: کاربر فقط به گوشی نگاه می کند و سپس به آرامی سرش را به دنبال یک دایره می چرخاند. بنابراین صورت در حالت های مختلف ثبت می شود. حالا قفل صفحه نمایش آماده فعالیت است. این روش ثبت سریع و شگفت آور می تواند در مورد الگوریتم های یادگیری اساسی چیزهای زیادی به ما بگوید. به عنوان مثال، شبکه های عصبی در FaceID تنها عمل طبقه بندی را انجام نمی دهند. انجام طبقه بندی برای یک شبکه عصبی به معنای یادگیری این است که آیا شخصی که به آیفون نگاه می کند کاربر واقعی آن است یا خیر. بنابراین باید از برخی داده های آموزشی جهت پیش بینی “درست” یا “نادرست” استفاده کند. اما علی رغم موارد متعدد استفاده از دیپ لرنینگ ، در اینجا این رویکرد مؤثر نیست. ابتدا شبکه عصبی باید با استفاده از داده های جدید به دست آمده از چهره کاربر، آموزش ببیند. این امر نیازمند زمان، انرژی و داده های آموزشی از چهره های مختلف برای تشخیص تصویر است. بعلاوه، این روش امکان آموزش اپل در حالت آفلاین را فراهم نمی کند. اما FaceID با شبکه عصبی پیچشی Siamese (توضیح در بخش بعد) طراحی شده که در حالت آفلاین توسط اپل برای ثبت چهره آموزش می بیند.
چهره ها و اعداد در شبکه های عصبی ( شبکه عصبی Siamese )
یک شبکه عصبی Siamese اساسا از دو شبکه عصبی یکسان تشکیل شده است که تمامی وزن ها را نیز به اشتراک می گذارد. این معماری می تواند محاسبه فاصله بین نوع خاصی از داده ها مانند تصاویر را بیاموزد. به این صورت که داده از طریق شبکه Siamese منتقل شده و شبکه عصبی آن ها را در یک فضای n بعدی ترسیم می کند. سپس به شبکه آموزش داده می شود تا این ترسیم را تا زمانی که نقاط مختلف داده ها در طبقه بندی های مختلف تا حد ممکن به یکدیگر نزدیک شوند، ادامه دهد. در دراز مدت، شبکه یاد می گیرد که مهمترین ویژگی ها را از داده ها استخراج کرده و آن ها را در یک آرایه فشرده سازی کرده و یک ترسیم معنی دار ایجاد کند. برای درک درست این موضوع تصور کنید که چگونه نژادهای مختلف سگ ها را با استفاده از یک نمودار کوچک توصیف می کنید؟ به این صورت که سگ های مشابه، نمودارهای نزدیک تری دارند. احتمالا برای رمزگذاری رنگ سگ از یک عدد استفاده می کنید، برای مشخص کردن اندازه سگ از عددی دیگر، برای شکل گوش ها از عددی دیگر و غیره. به این ترتیب، سگ هایی که به یکدیگر شباهت دارند، نمودارهایی مشابه یکدیگر خواهند داشت. یک شبکه عصبی Siamese می تواند یاد بگیرد که این کار را برای شما انجام دهد، مشابه کاری که یک کدگذار خودکار انجام می دهد.
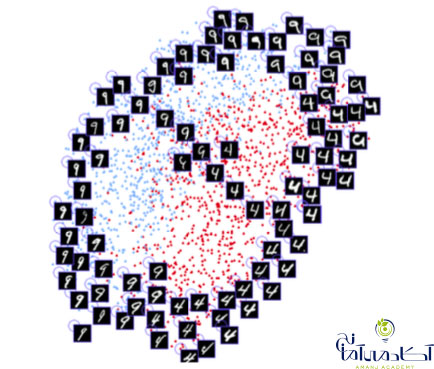
توجه کنید که معماری شبکه عصبی چگونه شباهت بین ارقام را یاد می گیرد و به طور خودکار آنها را در دو بعد دسته بندی می کند. تکنیک مشابهی روی صورت ها اعمال می شود.
با استفاده از این تکنیک می توان از تعداد زیادی چهره برای آموزش استفاده کرد تا تشخیص دهد که کدام چهره بیشترین شباهت را دارد. با داشتن بودجه کافی و قدرت محاسباتی (همانند اپل )، می توانید از مثال های سخت تری نیز استفاده کنید تا شبکه عصبی به مواردی همچون دوقلوها ، حملات خصمانه (ماسک) و غیره واکنش نشان دهد.
مزیت نهایی استفاده از دیپ لرنینگ در تشخیص تصویر
اینکه شبکه می تواند کاربران مختلف را بدون هیچ آموزش دیگری تشخیص داده و محاسبه کند که چهره کاربر، پس از گرفتن چند عکس در هنگام تنظیم اولیه، در نقشه نهفته چهره ها قرار دارد یا خیر. علاوه بر این ، FaceID قادر است با تغییرات در ظاهری شما سازگار شود : هم تغییرات ناگهانی (به عنوان مثال ، عینک ، کلاه ، آرایش) و هم تغییرات جزئی (مانند موهای صورت). این کار با اضافه کردن بردارهای چهره مرجع در این نقشه انجام می شود ، که بر اساس ظاهر جدید شما محاسبه می شود.

هنگامی که ظاهر شما تغییر می کند، FaceID سازگار می شود
اجرای FaceID در Keras
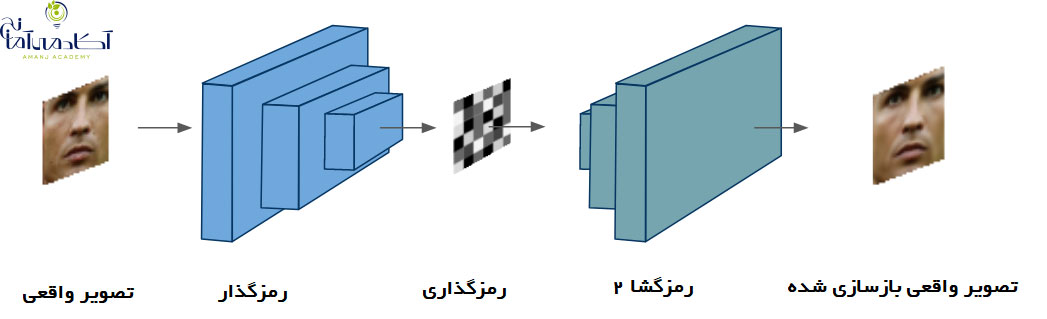
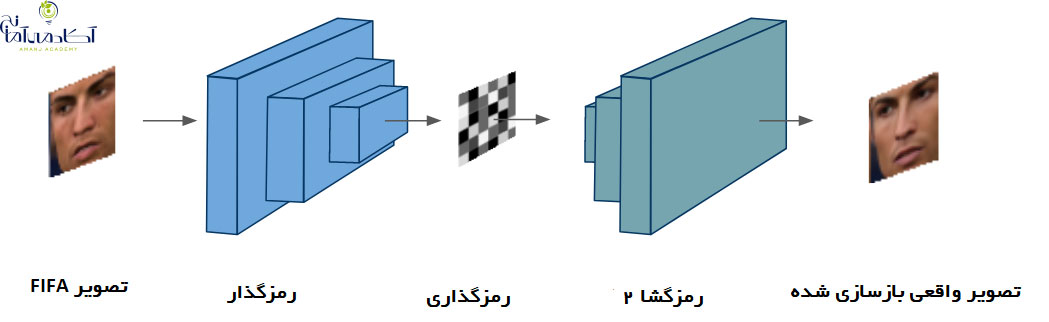
در مورد همه پروژه های دیپ لرنینگ اولین چیزی که ما نیاز داریم داده است. ایجاد مجموعه داده های ما به زمان و همکاری بسیاری از افراد نیاز دارد و این می تواند بسیار چالش برانگیز باشد. به همین دلیل از مجموعه داده های چهره RGB-D موجود در اینترنت کمک گرفتیم. در این مجموعه داده، افراد با اشکال مختلف و جهات مختلف وجود دارند. همان طور که در هنگام استفاده از آیفون اتفاق می افتد.
در ابتدا یک شبکه عصبی پیچشی بر اساس معماری SqueezeNet ایجاد کردیم. شبکه عصبی به شکلی آموزش داده می شود که فاصله بین تصاویر یک شخص را به حداقل رسانده و فاصله بین تصاویر اشخاص مختلف را به حداکثر برساند. پس از آموزش ، شبکه قادر است چهره ها را در آرایه های 128 بعدی ترسیم کند. به گونه ای که تصاویر یک شخص در کنار هم طبقه بندی شده و از تصاویر افراد دیگر فاصله دارد. این بدان معنی است که برای باز کردن قفل، شبکه فقط باید فاصله بین تصاویر ذخیره شده در مرحله ثبت چهره و تصویری که در هنگام باز کردن قفل دریافت می کند، محاسبه کند. اگر فاصله زیر یک آستانه مشخص باشد، (هرچه کمتر باشد از امنیت بیشتری برخوردار است) قفل دستگاه باز می شود.
آزمایش شبیه سازی FaceID
حال نحوه عمل این مدل را بررسی می کنیم. با شبیه سازی یک چرخه معمول FaceID. ابتدا ثبت چهره کاربر. سپس مرحله باز کردن قفل چه توسط کاربر (که باید موفقیت آمیز باشد) یا توسط افراد دیگرکه نباید قادر به باز کردن دستگاه باشند.
با ثبت چهره شروع می کنیم: یک سری عکس از یک شخص را از مجموعه داده گرفته و مرحله ثبت چهره را شبیه سازی می کنیم.

مرحله ثبت تصویر برای یک کاربر جدید با الهام از روند FaceID
حال ببینیم چه اتفاقی می افتد اگر همان کاربر سعی کند با حالت های مختلف چهره قفل دستگاه را باز کند.

فاصله صورت در فضای تعبیه شده برای همان کاربر
از طرف دیگر ، تصاویر RGBD از افراد مختلف به طور متوسط فاصله 1/1 را ایجاد می کند.

فاصله های چهره در فضای تعبیه شده برای کاربران مختلف
بنابراین، آستانه ای در حدود 4/0 باید برای جلوگیری از باز کردن قفل دستگاه توسط دیگران کافی باشد.
آموزش دیپ لرنینگ را در آکادمی آمانج تجربه کنید.


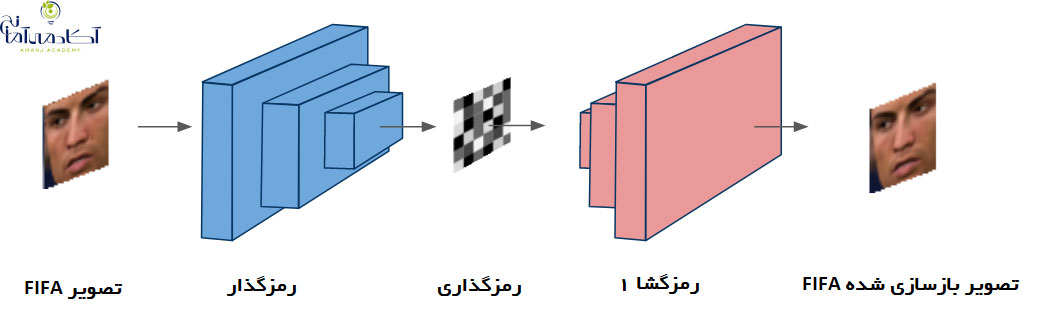
 چهره های
چهره های